一致性哈希是一种路由算法,可以在多节点存储数据时保证数据均匀分布,从而有效避免数据倾斜和数据热点问题。亚马逊 Dynamo 数据库的分区组件采用了一致性哈希算法,Apache Cassandra 集群的数据分区也采用一致性哈希算法。
路由算法的特点
数据库分库分表是一致性哈希算法的典型应用场景是。数据库分库分表有两种拆分方式,一种是业务角度的垂直拆分,一种是数据角度的水平拆分。水平拆分时,每张表对应一个数据分区,对于每一条数据,都需要选择一个数据分区进行存储。选择时的规则就是路由算法,也就是一致性哈希算法发挥作用的舞台。路由算法有两个关键信息——分区键和候选分区,分库分表的路由算法就是根据数据的分区键从候选分区中选出一个分区。
最简单的分区法是哈希取模法。先计算出分区键的哈希值,然后对候选分区的数量取模,选择结果对应的分区,对应的公式为 idx = hash(key) % n。如果是数字主键,可以省略计算哈希值的步骤。
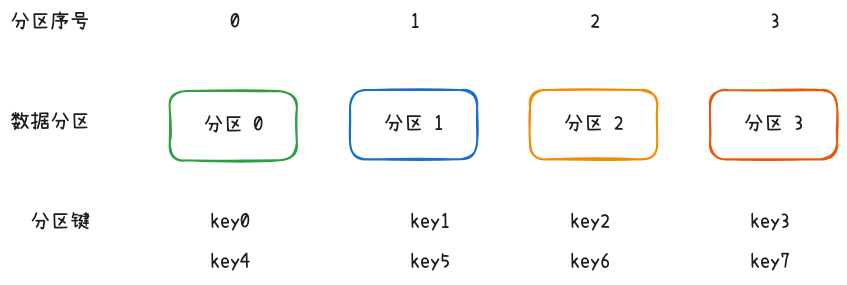
哈希取模法的缺点在于不具备扩展性,一旦候选分区数量变动,几乎所有键都需要重新分配分区,这在数据存储领域是相当大的开销。
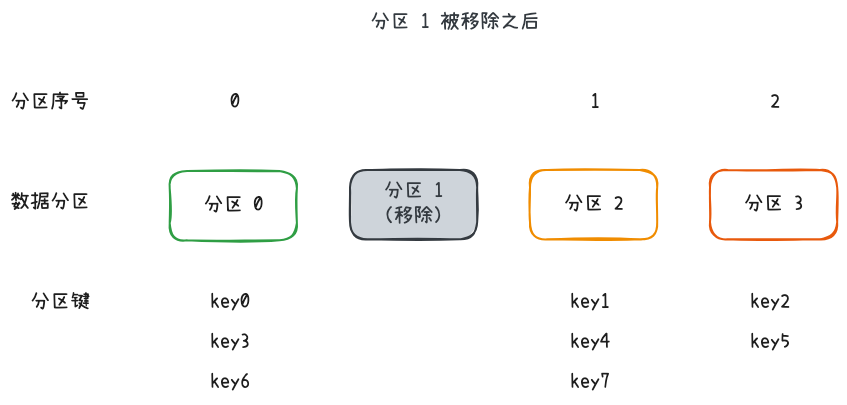
另一种常见的分区法是范围分区法,选取数据的某些特殊属性作为分区键,为每个数据分区分配不同的范围,按范围匹配数据和分区。范围分区键可以选取主键、时间戳这类数字属性,也可以选取地理位置、部门信息等具备分类性质的属性。新增或移除分区时,可以只调整部分分区范围,避免全局调整。
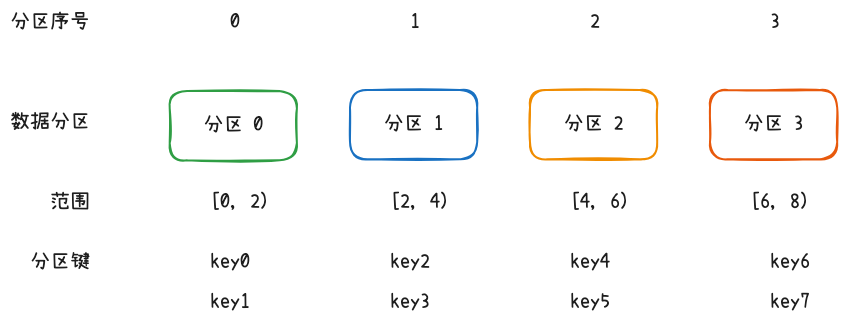
范围分区法的问题在于无法保证均匀分布。主键还好,时间戳、地理信息这类属性,与人的活动相关,白天的数据一般比晚上多,人口密集区域的数据一般比偏远区域的数据量多。这种数据不均匀分布在存储上表现为某些分区的数据量远超同侪,造成了额外的存储压力,这种存储不均匀被称为数据倾斜;在数据访问频率方面,不均匀分布的数据会造成某些分区被访问频率高于其他分区,这种读写上的不均匀被称为数据热点。数据倾斜和数据热点的问题在于要特殊关照某些倾斜或热点分区,无法统一管理,增加了额外的数据管理成本。
从上面两个例子中,大致可以归纳出路由算法的特点:
- 可扩展性,可以灵活调整分区;
- 分布均匀,不会出现数据倾斜问题和数据热点问题。
本文的主角一致性哈希算法就具备这两个优良品质。
一致性哈希算法的原理
一致性哈希算法的核心结构是哈希环。哈希环类似环状数组,下标为哈希值。用哈希函数计算出数据分区的哈希值,将分区映射到哈希环上。计算数据所属分区时,用相同的哈希函数计算出分区键的哈希值,顺时针找到的第一个分区就是所属分区。在这个规则下,两个节点之间的范围都归后一个节点所有。
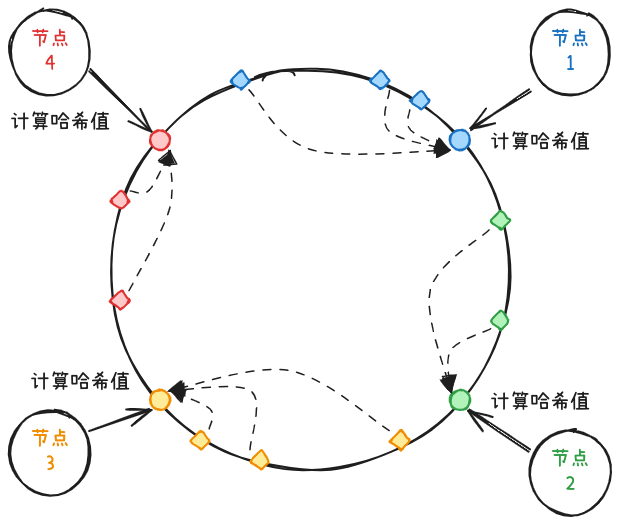
哈希环维护了数据与分区的路由关系。
一致性哈希算法能保证数据均匀分布,底层利用了哈希值均匀分布的特性。选取的哈希函数应当保证哈希值均匀分布,这样才能保证哈希环上的数据分布也越均匀。
增加分区时,只需要将哈希环上新增分区与前一个分区之间的数据移动到新分区,大部分数据分区无需改变。
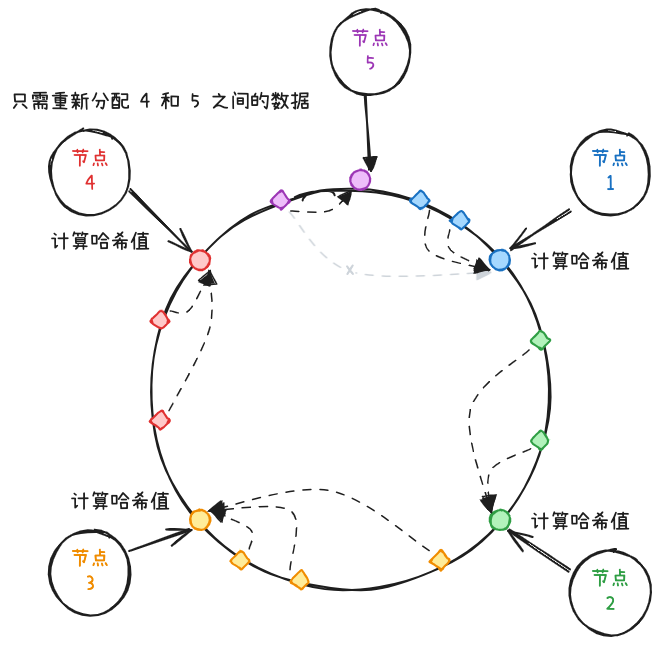
删除分区时,也只需要将被移除分区的数据重新分配到哈希环上的下一个分区,大部分分区不需要改变。
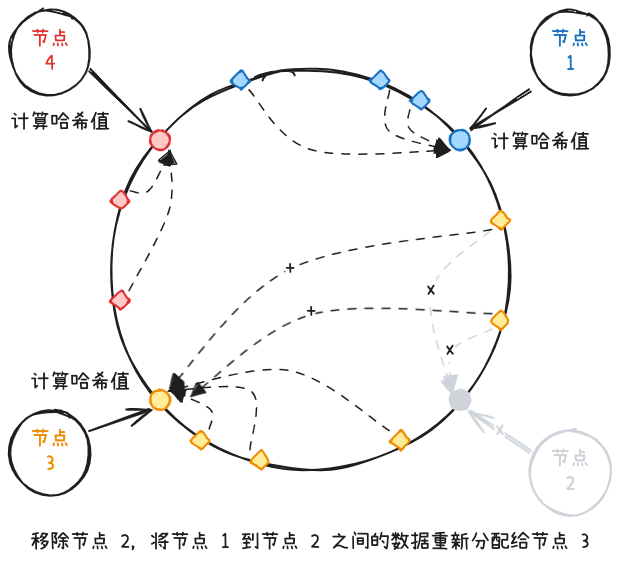
一致性哈希算法的一大优点就是扩展成本低,增删分区时能保证大部分分区无需改动。
至于缺点,其实从上面例子就可以看出,分区数较少时,可能出现数据倾斜问题。例如上图移除节点 2 后,节点 3 的数据量显著高于其他节点。节点数据较少时,很难保证哈希环上所有数据分区大小相同。
对于因为分区数量少而导致数据倾斜问题,可以通过虚拟节点来解决。虚拟节点是真实节点的“分身”,每个真实节点对应多个虚拟节点。哈希环上按照虚拟节点来分配分区。虚拟节点数量增加,键的分布就会变得更均匀。使用 100 个虚拟节点时,每个真实节点承载的数据量浮动在 10% 左右;使用 200 个虚拟节点时,数据量浮动为 5%。
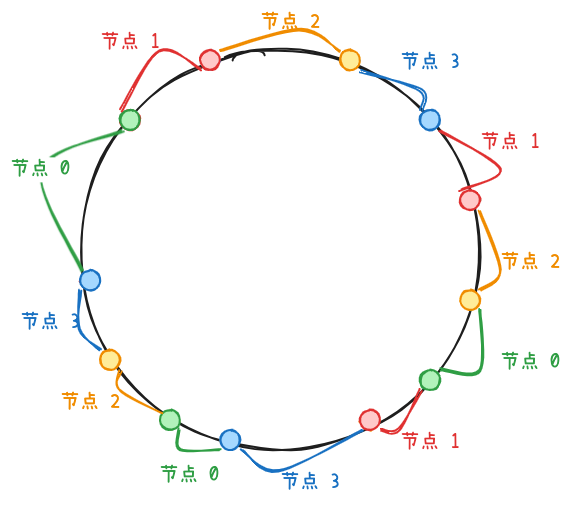
一致性哈希算法通过哈希环保证了可扩展性,通过虚拟节点使数据分布更均匀。
实现一致性哈希算法
要实现一致性哈希算法,最核心的问题就是用什么数据结构表示哈希环。一个直观的办法是环形数组。用环形数组记录虚拟节点的位置,然后根据键的哈希值在环形数组顺时针查找虚拟节点。但用环形数组存在两个问题。一是空间占用高。环形数组的长度决定了所有分区的存储上限,通常会选用为 $2^{32}$ 或者更大。为此需要分配一个长度为 $2^{32}$ 的数组。但实际只需要存储虚拟节点的位置信息,键的位置可以通过计算得出,且记录键的位置信息毫无意义。数组存在很大空间浪费。另一个问题是查找效率不高。每一次为键查找分区都需要在数组空荡荡的空间里查找零星几个虚拟节点,几近于大海捞针。当数组长度为 l 虚拟节点总数为 n 时,平均查找效率为 $O(\frac{l}{n})$。
更好的选择是使用二叉查找树。用 BST 存储虚拟节点的哈希值,可以在 $O(log n)$ 的时间复杂度内查到任意哈希值的下一个有效节点。同时只需要存储虚拟节点的位置,总体空间开销大大减少。
实际实现中,采用 TreeMap 来表示哈希环。TreeMap 内部采用红黑树结构,这是一种自平衡二叉树,可以有效避免树退化成链表导致的性能劣变。
1 | public class ConsistentHashRouter { |
根据哈希值,查找前驱节点和后继节点的方法。为了体现出环的概念,在查找前驱节点为空时,取 TreeMap 第一个节点,查找后继节点为空时,取 TreeMap 的最后一个节点。总体时间复杂度为 $O(log n)$。
1 | private VirtualNode previousVirtualNode(int hash) { |
根据键查找分区时,先从哈希环中找到对应虚拟节点,然后根据虚拟节点找到对应物理节点。
1 | public Node route(String key) { |
为了便于查找物理节点对应的虚拟节点,使用 HashMap 记录了两者的映射关系。在移除节点时,可以根据映射快速判断节点是否存在,以及获取对应的虚拟节点。为了便于数据迁移,在增删节点时,返回需要迁移数据的节点。
1 | // 记录物理节点和虚拟节点的映射关系 |
哈希函数的选取
一致性哈希算法中,对于哈希函数有以下要求:
- 快速,保证性能;
- 哈希值均匀分布,哈希空间内的每个值出现概率均等,保证所有数据均匀分布于哈希环上;
- 具备雪崩效应(avalanche),输入发生微小改变也能使得输出的哈希值大为不同,从而保证序列型分区键能均匀分布在哈希环上。
对于抗碰撞性要求不高,即使出现两个键的哈希值相同,也只是代表两个键属于同一个分区,所以只需要基本的抗碰撞性即可。
因此,可以舍弃计算成本更高的密码学哈希算法,比如 MD5、SHA-1、SHA-256、BLAKE2 等,节约 CPU 资源,选择非密码学哈希算法,比如 MurMurHash3、xxHash、CRC32(有一个在较新 CPU 上性能更好的版本 CRC32c)。
一个比较均衡的选择是 MurMurHash3。Java 平台可以通过 commons-codec 或 guava 包引入。
还有一个需要注意的点是哈希值的正负号,哈希函数计算出的哈希值可能为负数。用 TreeMap 表示哈希环时,不需要担心哈希值为负数的情况,但如果选择其他数据结构,需要考虑是否支持负数。
虚拟节点数量的选取
在总共十万个键的情况下,统计不同虚拟节点数量下数据的分布情况,使用变异系数作为指标。变异系数是标准差与平均值的比值,变异系数越大,数据的变异程度越大,也就是越不均匀。
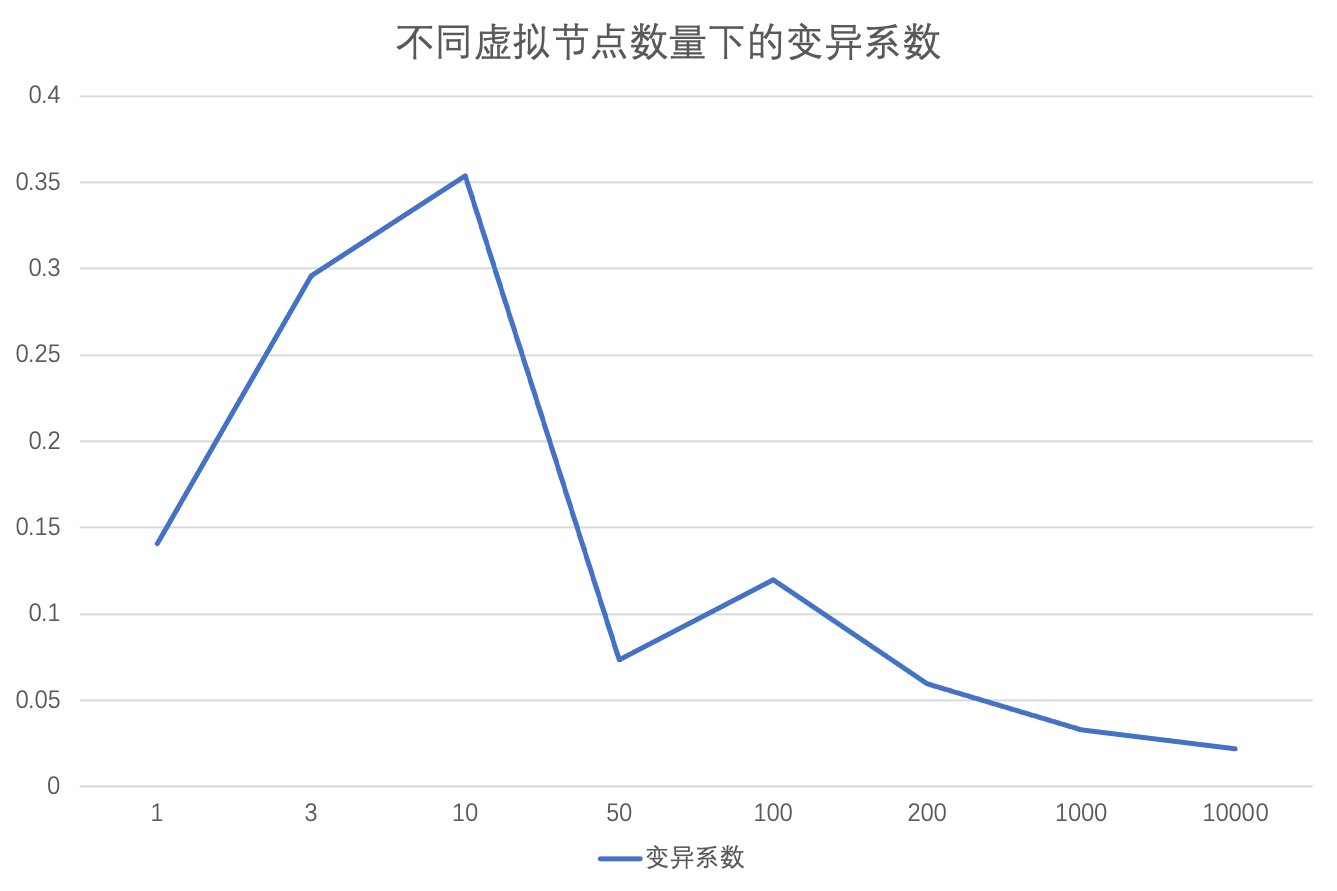
可以看出,整体呈现下降趋势,虚拟节点越多,数据分布越均匀。
原始数据按顺序分别为:虚拟节点数量、各节点数据量、各节点数据比例、变异系数。
1 | 1, [33428, 39020, 27552], [0.33428, 0.3902, 0.27552], 0.14046809744564778 |
尚需完善的地方
线程安全
数据路由功能通常会涉及到多线程环境,因此需要保证增删节点方法与路由方法的线程安全。考虑到增删节点的频率远低于路由操作,一个比较简单的办法是采用读写锁,并且对读锁优化。具体实现可以参考文末的示例代码。
当然,也可以采用其他性能更高的读多写少场景的线程安全方案,比如写时复制。
分布式一致性
存在多个工作节点共同承担路由功能时,需要保证所有工作节点上的哈希环一致。比较简单的做法是使用消息队列。所有工作节点监听消息队列,当数据分区变动时,将变动信息封装为消息发送至消息队列,只要工作节点正确消费消息,就能确定工作节点本地的哈希环是一致的。
本文介绍了一致性哈希算法的原理,核心是哈希环的应用。同时还提供了一个基础实现,并对一些细节之处进行讨论。按照惯例,代码已经上传 GitHub。