路由算法是为了解决将 n 个苹果 🍎 均分到 k 个篮子 🧺 中的问题,难点在于随时都可能增加篮子或者减少篮子。路由算法有两个要求,一是每个篮子里的苹果数量差不多,二是增减篮子时需要移动的苹果数量尽可能少,前者称为分布均衡,后者称为可扩展。
存储领域,路由算法的苹果指的是需要存储的数据,篮子指的是提供存储功能的节点。存储领域流传较广的路由算法是一致性哈希算法,但还有另一种同样基于哈希函数的算法,也兼具分布均衡和可扩展的特点,即本文的主角——集合点哈希(Rendezvous hashing)。
集合点哈希的原理
集合点哈希算法的核心思想是对于每个苹果,分配一个随机的篮子序列,选择序列中的第一个篮子作为容器。
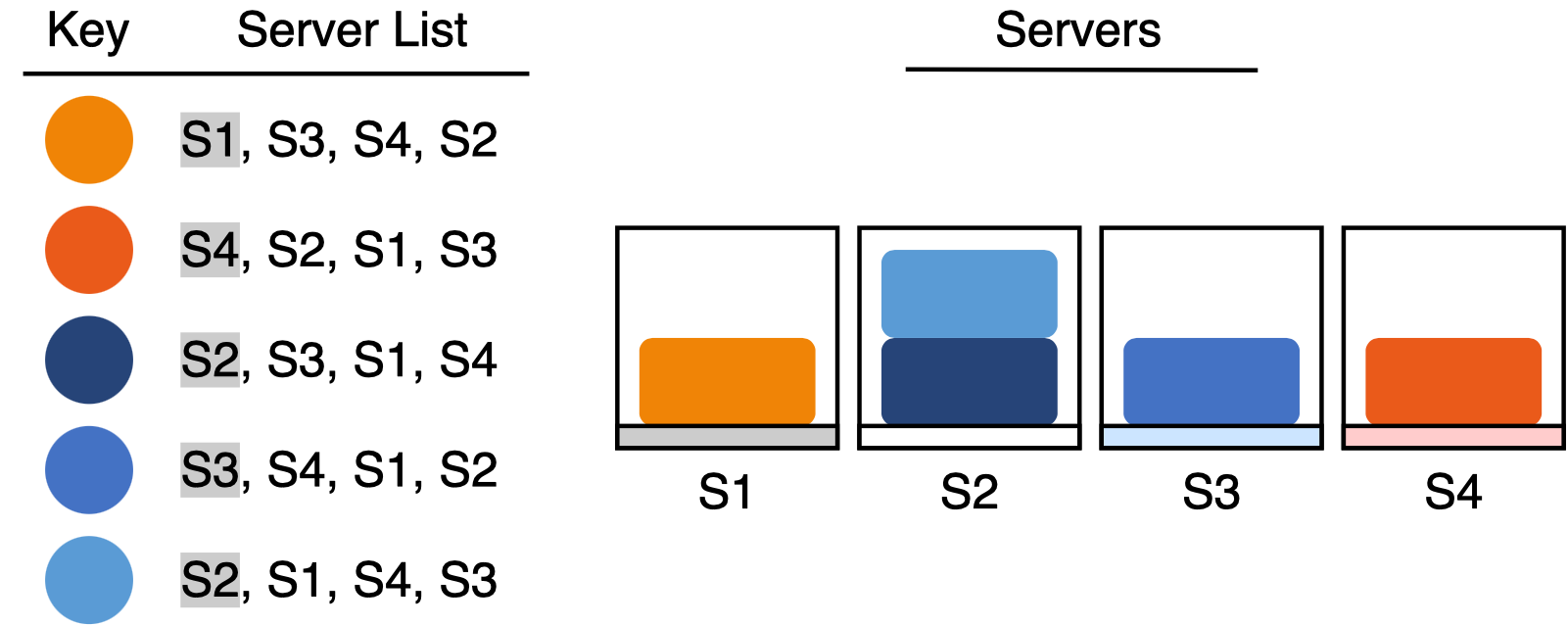
当序列中第一个篮子变得不可用时,选择第二个篮子。这样就保证了减少节点时,只需要移动被移除节点上的键,其他节点上的键不受影响。从上图移除 S2 节点时,只有原本第一选择是 S2 的键需要迁移。因为序列的第二个篮子是随机的,原本 S2 上的键会被平均分配给剩下的节点,不会导致某一个节点的数据量激增的数据倾斜问题。
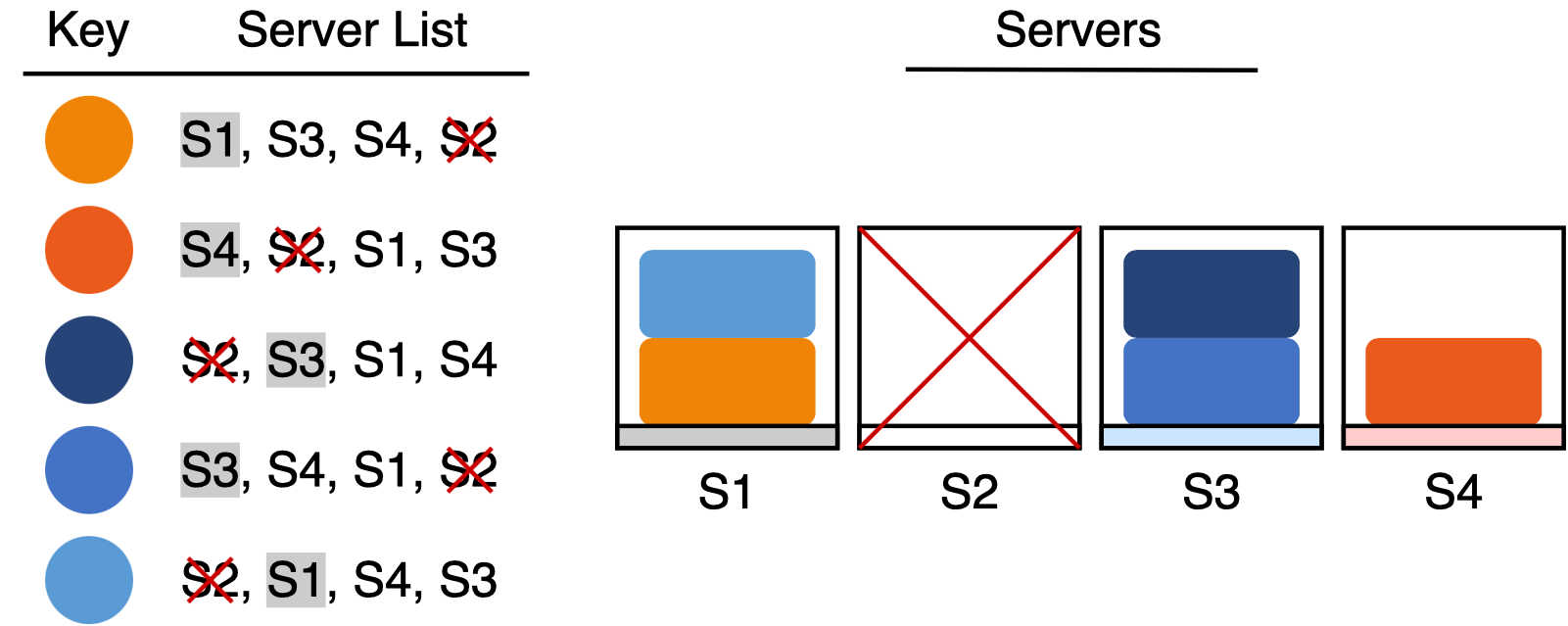
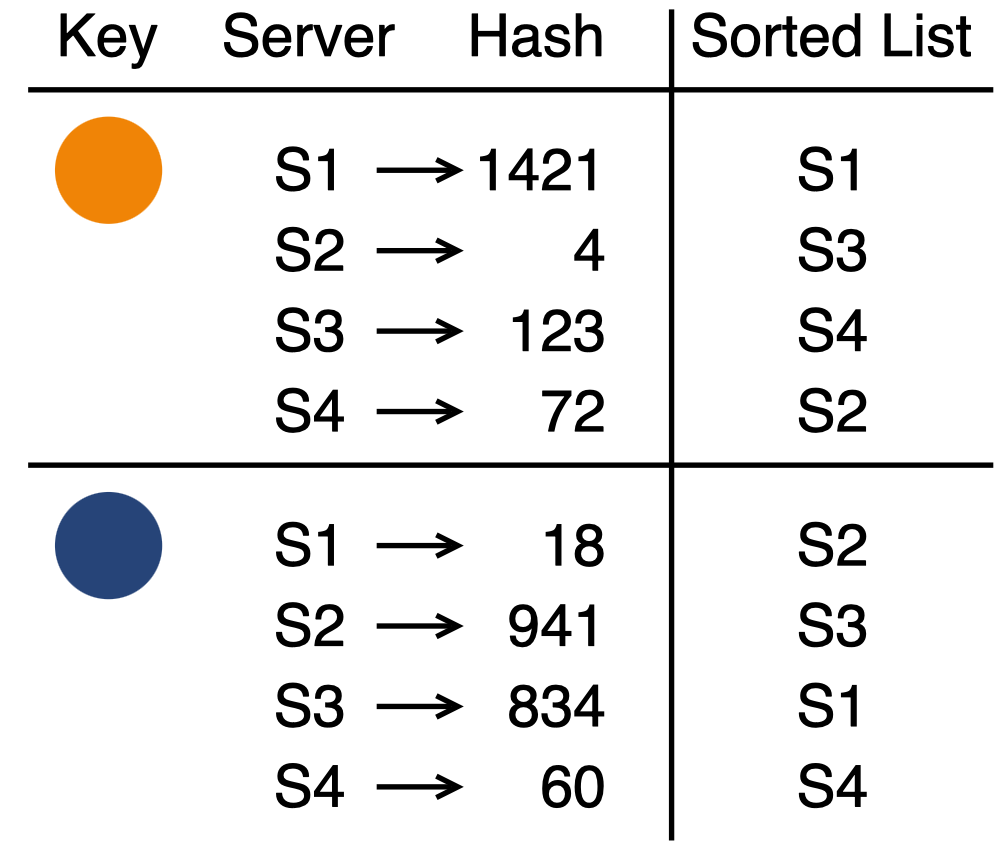
实际实现中,不需要真正地记录每一个苹果的篮子序列,只需要保证篮子不变时,每个苹果对应的篮子序列也不会变即可。要实现这种功能,一个行之有效的办法是利用哈希函数的确定性,相同的键能得到相同的哈希值。在为苹果挑选篮子时,综合苹果的特征和篮子的特征,作为参数计算出哈希值,这样就得到了一个哈希值列表,然后从中选择哈希值最大(或最小)的篮子作为最终结果。
之所以综合苹果的特征和篮子的特征,是为了保证不会为所有键生成相同的序列。
路由方法实现代码:
1 | public Node route(String key) { |
相较于一致性哈希算法,集合点哈希不需要维护哈希环,整体实现更为简洁。
集合点哈希的优点
集合点哈希最显著的优点是支持节点加权排序。某些节点容量更大,能够存储更多的数据,就可以分配更大的权值。此时需要调整计算公式,不能单纯将权值乘以哈希值。
$$
- \frac{W_{i}}{ln;s_{i}}
$$
其中,$s_{i}$ 代表节点对应哈希值与哈希空间上限的比值,$s_{i} = \frac{h_{i} + 1}{Max_H}$,取值范围为 (0, 1]。$ln$ 代表自然对数 $log_e$。
加权版本的路由方法:
1 | public WeightedNode route(String key) { |
对于节点权重是否影响分配,可以通过单元测试验证。
1 |
|
集合点哈希的另一个优点是内存占用低,因为不需要额外的信息,只要节点集合。
此外,分布式环境下,集合点哈希只需要不同节点同步集合信息即可。除了通过消息队列传递节点变更信息的方案,还可以参照 Redis Cluster 采用 Gossip 协议实现去中心化设计。
集合点哈希的缺点
挑选节点时需要为每个节点计算哈希值,然后选择哈希值最大的节点,时间效率为 O(n),在节点数量较多时性能差。
每次路由都需要为每个节点计算一遍哈希值,需要消耗更多 CPU 资源。
集合点哈希算法在增加节点时可能出现问题。新增一个篮子,会改变某些苹果的篮子序列的第一名,需要将这些苹果迁移到新的篮子。
迁移方案包括主动迁移和被动迁移。主动迁移要么遍历所有数据,要么记录数据归属信息,成本都太高,通常不会考虑。被动迁移具备可行性,在访问数据时发现数据不存在,就自动完成迁移。这代表集群的「自愈性」。
因此,集合点哈希的可扩展性是有限制的。只能在可以“自愈”的场景使用。比如分布式缓存,新增节点后,某些 key 的第一选择会变为新增节点,此时数据还未迁移到新节点,初次访问会 miss,从数据库读取数据后才恢复正常。
与一致性哈希对比
集合点哈希与一致性哈希相比,除了实现简单、内存开销小、支持加权外,集合点哈希数据更加均匀。
通过统计不同键数量下各个节点承载键数量,计算出变异系数,得到节点承载的波动程度。变异系数是标准差与平均值的比值,变异系数越大,数据的变异程度越大,也就是越不均匀。
3 个物理节点,键的数量分别为 10000、100000、1000000、5000000,计算一致性哈希算法和集合点哈希算法的变异系数。这里一致性哈希算法使用 1000 个虚拟节点,最大程度屏蔽误差。
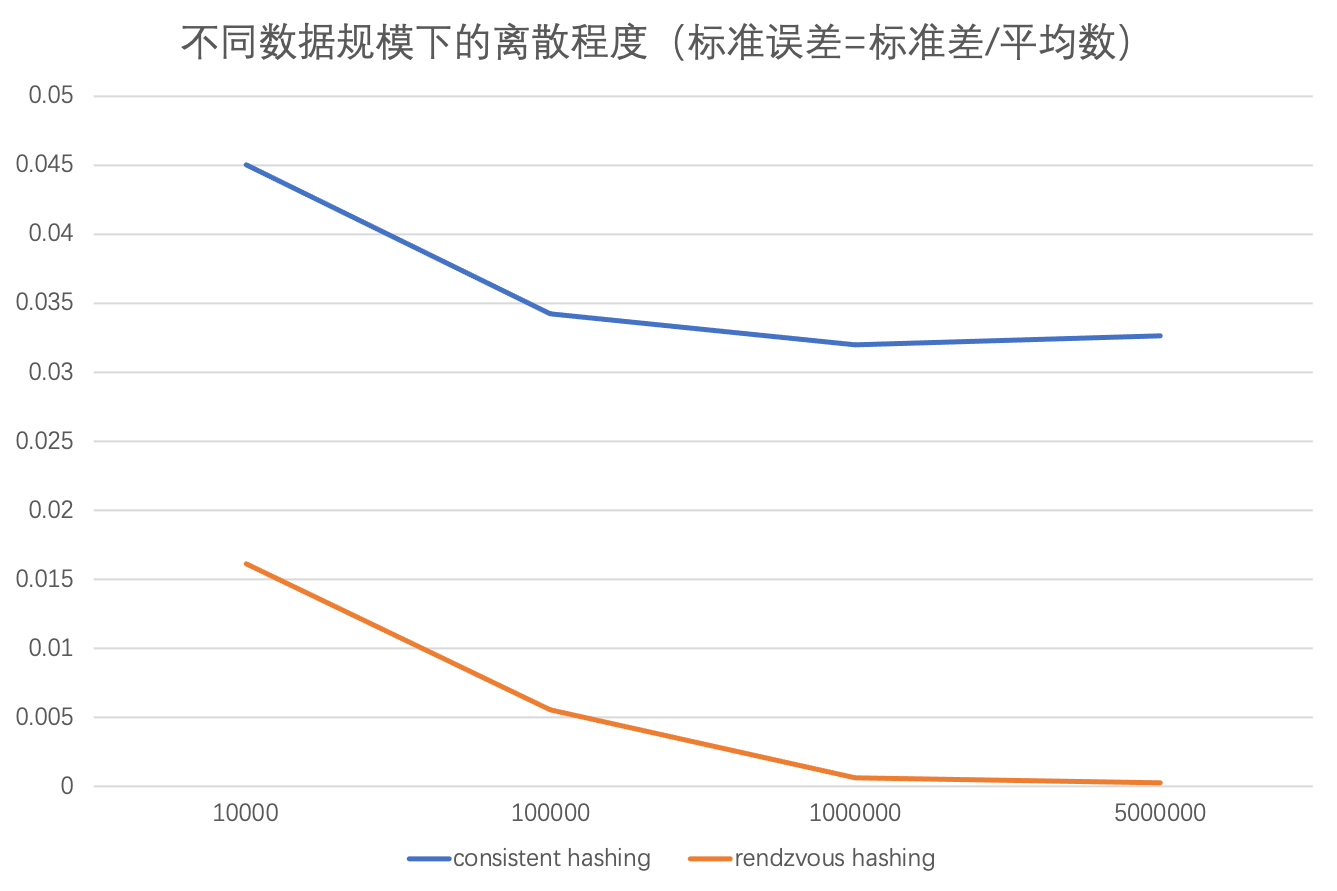
从图表中可以看出,集合点哈希明显比一致性哈希更均匀。
原始数据:键数量、各节点数量量、各节点数据比例、变异系数。
一致性哈希算法原始数据:
1 | 10000, [3160, 3526, 3314], [0.316, 0.3526, 0.3314], 0.04501288704360118 |
集合点哈希原始数据:
1 | 10000, [3264, 3341, 3395], [0.3264, 0.3341, 0.3395], 0.01612637591029057 |
适用场景
集合点哈希算法适合中小型分布式缓存,内存占用少,实现简单,但由于水平扩展时会导致错误路由结果,所以要求缓存节点具备「自愈性」。
本文代码已经上传 GitHub。